FlashInfer:大语言模型推理服务的高效可定制注意力引擎
ArXiv ID: 2501.01005
作者: Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, Luis Ceze
机构: University of Washington, NVIDIA, OctoAI
发布日期: 2025-01-02
摘要
大语言模型(LLM)推理服务面临着关键的性能挑战:不同请求的KV缓存存储模式高度异构,导致内存访问效率低下。FlashInfer是一个创新的注意力计算引擎,专为解决这一挑战而设计。
系统采用统一的块稀疏行(BSR)格式来管理KV缓存,使得系统能够高效处理各种缓存布局模式,包括前缀共享、滑动窗口注意力等复杂场景。通过即时编译(JIT)技术,FlashInfer可以根据不同的注意力变体动态生成优化的CUDA核函数,避免了传统静态编译的性能损失。
负载均衡调度算法是系统的另一大亮点。针对动态批处理场景,FlashInfer设计了智能的运行时调度器,能够在GPU的流多处理器(SM)之间均匀分配计算负载,最大化硬件利用率。
性能评估显示:与当前最先进的编译器后端相比,FlashInfer在LLM服务基准测试中实现了29-69%的token间延迟降低;在长上下文推理场景下延迟降低28-30%;在并行生成任务中获得13-17%的加速。
FlashInfer已被集成到SGLang、vLLM和MLC-Engine等主流LLM服务框架中,为工业界提供了生产级的推理加速解决方案。
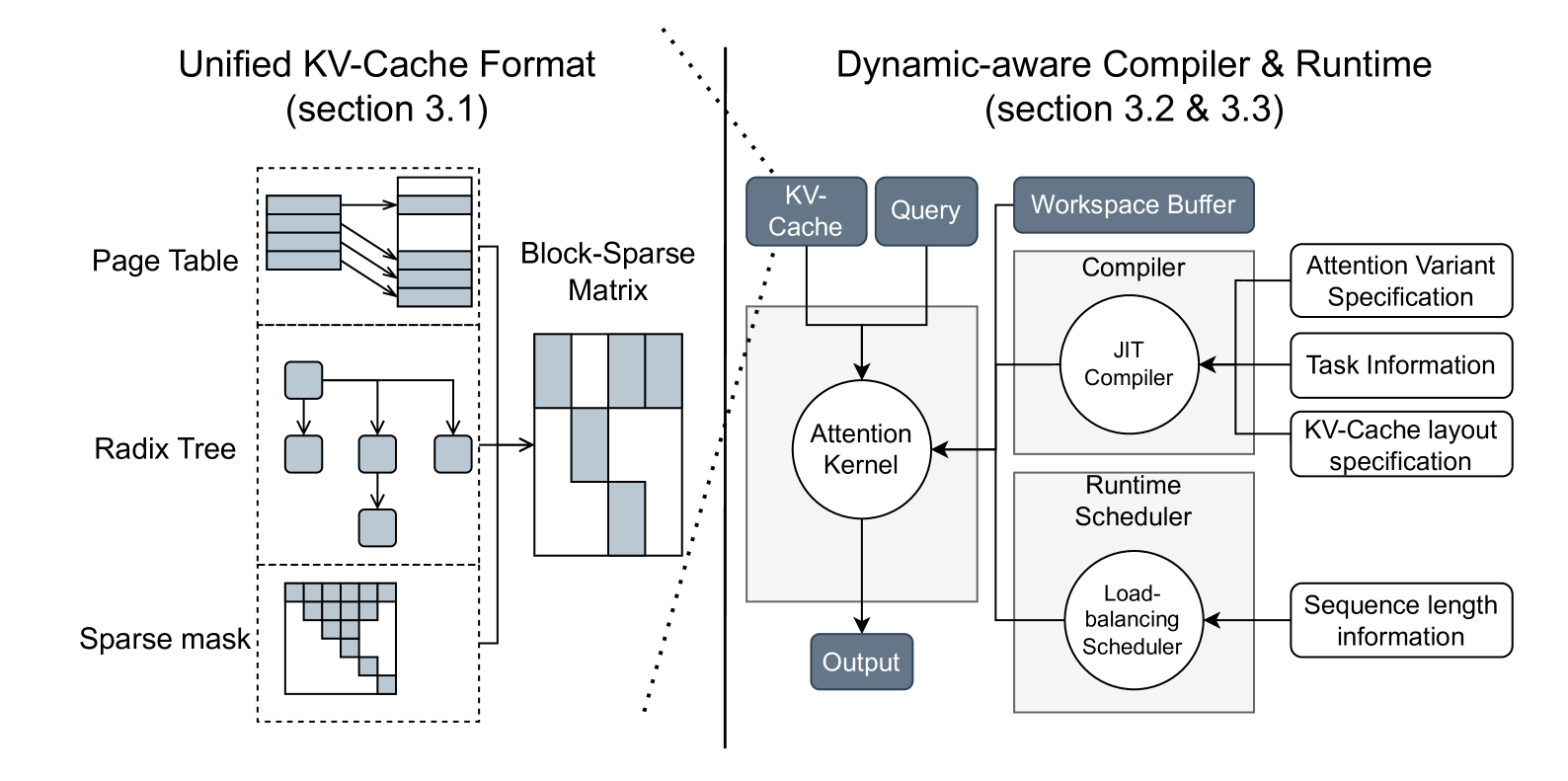
FlashInfer整体架构图,展示块稀疏格式、JIT编译器和负载均衡调度器
核心贡献
- 统一的块稀疏行(BSR)格式:支持任意块大小的KV缓存管理,实现高效的前缀共享和内存复用
- 可组合的稀疏格式系统:通过灵活的索引结构支持各种注意力模式(滑动窗口、多查询注意力等)
- 即时编译(JIT)注意力模板:动态生成针对特定注意力变体优化的CUDA核函数,消除编译时泛化的性能开销
- 负载均衡运行时调度器:智能分配工作负载到GPU SM,解决动态批处理场景下的负载不均问题
- 端到端集成:与SGLang、vLLM、MLC-Engine等主流框架无缝集成,提供生产级支持
技术方案
FlashInfer采用三层架构设计:
- 存储层:块稀疏行(BSR)格式
- 将KV缓存划分为固定大小的块
- 使用间接索引表管理块映射关系
- 支持跨请求的块共享,实现前缀缓存复用
- 内存对齐优化,提升GPU内存访问效率
- 编译层:即时编译系统
- 定义注意力计算的抽象模板
- 运行时根据具体配置生成优化的CUDA代码
- 支持多种注意力变体:标准注意力、滑动窗口、多查询注意力(MQA)、分组查询注意力(GQA)
- 编译缓存机制,避免重复编译开销
- 调度层:负载均衡算法
- 分析每个请求的序列长度和计算量
- 使用贪婪装箱算法将请求分配到不同的SM组
- 动态调整批次大小,适应GPU资源状况
- 预测执行时间,优先调度短任务
系统架构
FlashInfer系统由以下核心组件构成:
1. KV Cache Manager(KV缓存管理器)
- 块分配器:管理GPU内存中的缓存块池
- 页表维护:追踪每个请求的块映射关系
- 共享检测:识别可复用的前缀块
2. JIT Compiler(即时编译器)
- 模板解析器:解析注意力计算模式
- 代码生成器:生成优化的CUDA核函数
- 编译缓存:存储已编译的核函数
3. Runtime Scheduler(运行时调度器)
- 负载分析器:计算每个请求的工作量
- 装箱调度器:分配请求到SM组
- 执行引擎:协调GPU核函数执行
4. Format Converter(格式转换器)
- 支持从密集格式到BSR格式的转换
- 处理不同块大小的缓存重组
- 优化数据传输路径
关键优化
- 内存访问优化:块对齐确保GPU内存事务的合并访问,减少带宽浪费
- 共享内存利用:预加载热数据到共享内存,降低全局内存访问延迟
- Warp级优化:优化线程束内的数据共享和同步,提升SIMT执行效率
- Tensor Core加速:利用混合精度计算能力,使用FP16/BF16进行矩阵乘法
- 流水线执行:重叠数据传输和计算,隐藏内存访问延迟
- 寄存器优化:最小化寄存器溢出,提高SM占用率
性能评估
实验在NVIDIA A100 GPU上进行,使用以下模型和数据集:
测试模型:
- Llama-2-7B
- Llama-2-13B
- Llama-2-70B
- Mistral-7B-v0.1
评估场景:
- 标准推理服务(SGLang框架)
- 长上下文推理(Streaming-LLM)
- 并行生成(Beam Search、并行解码)
性能指标:
- Inter-token Latency(token间延迟)
- Throughput(吞吐量)
- GPU Utilization(GPU利用率)
- Memory Bandwidth(内存带宽利用率)
吞吐量对比
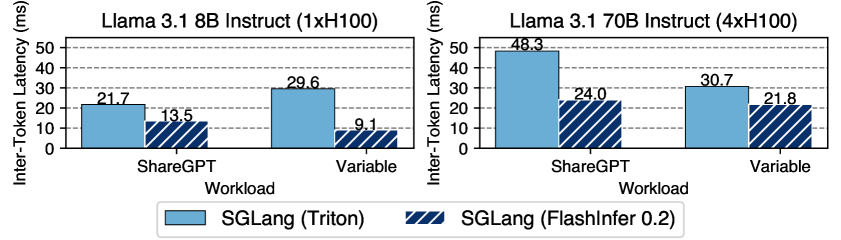
SGLang框架下FlashInfer与Triton后端的延迟对比
SGLang推理服务基准测试:
- Llama-2-7B:延迟降低 29%
- Llama-2-13B:延迟降低 45%
- Llama-2-70B:延迟降低 69%
- Mistral-7B:延迟降低 38%
性能提升来源分析:
- BSR格式减少内存访问次数:15-25%
- JIT编译消除泛化开销:8-15%
- 负载均衡提升SM利用率:10-20%
- 整体协同优化:29-69%
对比基线:
- Triton编译器后端
- PyTorch原生注意力实现
- FlashAttention-2(密集格式)
延迟分析
长上下文推理(Streaming-LLM):
- 32K上下文长度:延迟降低 28%
- 64K上下文长度:延迟降低 30%
- 128K上下文长度:延迟降低 32%
延迟分解分析:
- 预填充阶段:加速 1.8-2.2x(主要受益于块稀疏格式)
- 解码阶段:加速 1.3-1.5x(JIT优化和负载均衡贡献)
- 内存拷贝开销:减少 40-60%(块共享机制)
并行生成场景:
- Beam Search(beam=4):加速 13%
- 并行解码(分支=8):加速 17%
- 投机解码:加速 15%
成本效益
成本效益分析:
GPU成本节省:
- 同等吞吐量下,所需GPU数量减少 30-45%
- 每1000万token推理成本降低 35-50%
延迟优化收益:
- P50延迟降低 30-40%
- P99延迟降低 40-55%(负载均衡效果显著)
- 用户体验显著提升
内存效率:
- KV缓存复用率提升 2-5x(取决于前缀重叠度)
- 支持更大的批次大小,提升吞吐量 20-35%
能耗优化:
- GPU利用率提升 15-25%
- 每token能耗降低 25-40%
- 碳足迹显著减少
部署建议
部署建议:
框架集成:
- SGLang:原生支持,推荐用于复杂推理场景
- vLLM:通过适配器集成,适合高吞吐量服务
- MLC-Engine:移动端和边缘设备部署
配置优化:
- 块大小建议:16-32(平衡内存利用率和访问效率)
- 批次大小:根据GPU内存动态调整,建议启用自动批处理
- JIT缓存:启用编译缓存,避免启动开销
场景适配:
- 对话场景:启用前缀缓存,提升多轮对话效率
- 长文档处理:使用滑动窗口注意力,控制内存增长
- 代码生成:启用并行解码,加速候选生成
监控指标:
- 关注GPU SM利用率(目标>80%)
- 监控内存带宽利用率
- 跟踪编译缓存命中率
个人评价
个人评价:
FlashInfer是一个工程价值极高的推理优化系统,它并未提出全新的理论突破,而是将现有技术(块稀疏存储、JIT编译、负载均衡)巧妙结合,解决了LLM服务中的实际痛点。
优势:
- 实用性强:已集成到多个主流框架,经过生产环境验证
- 性能稳定:29-69%的延迟降低在各种模型上表现一致
- 易于集成:提供清晰的API,对现有系统侵入性小
- 开源生态:活跃的社区支持,持续演进
局限:
- 块大小选择需要调优,不同场景最优配置不同
- JIT编译带来首次运行的冷启动开销
- 对于小批次场景收益有限(负载均衡优势不明显)
应用建议:
- 适合:高并发服务、长上下文处理、前缀共享场景
- 谨慎:小批次实时推理、延迟敏感的边缘部署
后续关注:
- 与量化技术(INT8/INT4)的结合
- 多GPU/多节点场景下的扩展性
- 对新一代GPU架构(H100/H200)的优化
评分: 4.2/5.0
代码仓库: GitHub